In this blog, we will explore a very smart double mmap virtual memory mapping trick. In industry, a lot of ring buffer implementations exploit this trick to ease the implementation and boost performance.
Let’s first look at a very vanilla implementation of ring buffer using mmap.
struct circular_queue {
size_t size;
size_t write_index;
size_t read_index;
char *buffer;
};
struct circular_queue *create_queue(size_t size) {
assert(size % getpagesize() == 0);
struct circular_queue *queue = malloc(sizeof(struct circular_queue));
queue->size = size;
queue->write_index = 0;
queue->read_index = 0;
queue->buffer = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
return queue;
}
void enqueue(struct circular_queue *queue, char *data, size_t len) {
size_t remain = queue->size - queue->write_index;
size_t copy_to_tail = (remain >= len) ? len : remain;
size_t overflow = len - copy_to_tail;
memcpy(queue->buffer + queue->write_index, data, copy_to_tail);
memcpy(queue->buffer, data + copy_to_tail, overflow); // wrap around
queue->write_index = (queue->write_index + len) % queue->size;
}
mmap creates a virtual memory mapping of requested size into this process’s address space starting at queue->buffer. The caveat here for the ring buffer is that when it reaches the end of the buffer, it needs to take modulo operation and wraps around, which is annoying in implementation and not great for performance. An illustration is provided as follows:
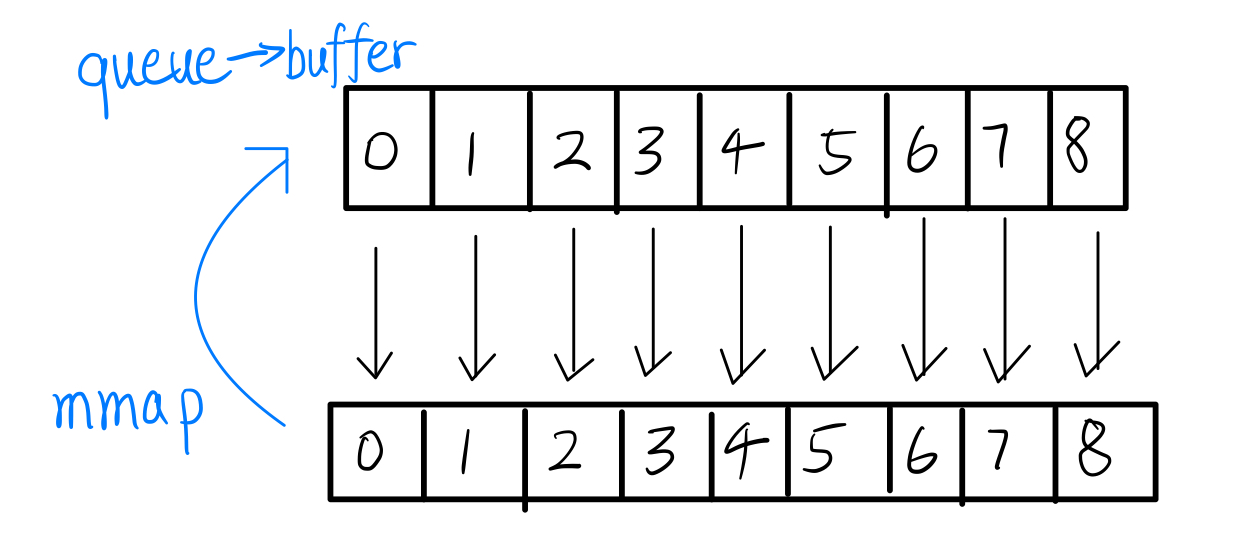
So the virtual memory mapping trick here we will use is that we will map the same chunk of memory array together tail to head. Imagine [v1, v2, ..., vm, v1, v2, ... , vm]. Then when the circular queue is reaching the end when inserting elements, it could temporarily “overwrite the buffer end” and the insertion will natually be wrapped around. An illustration is provided as follows:
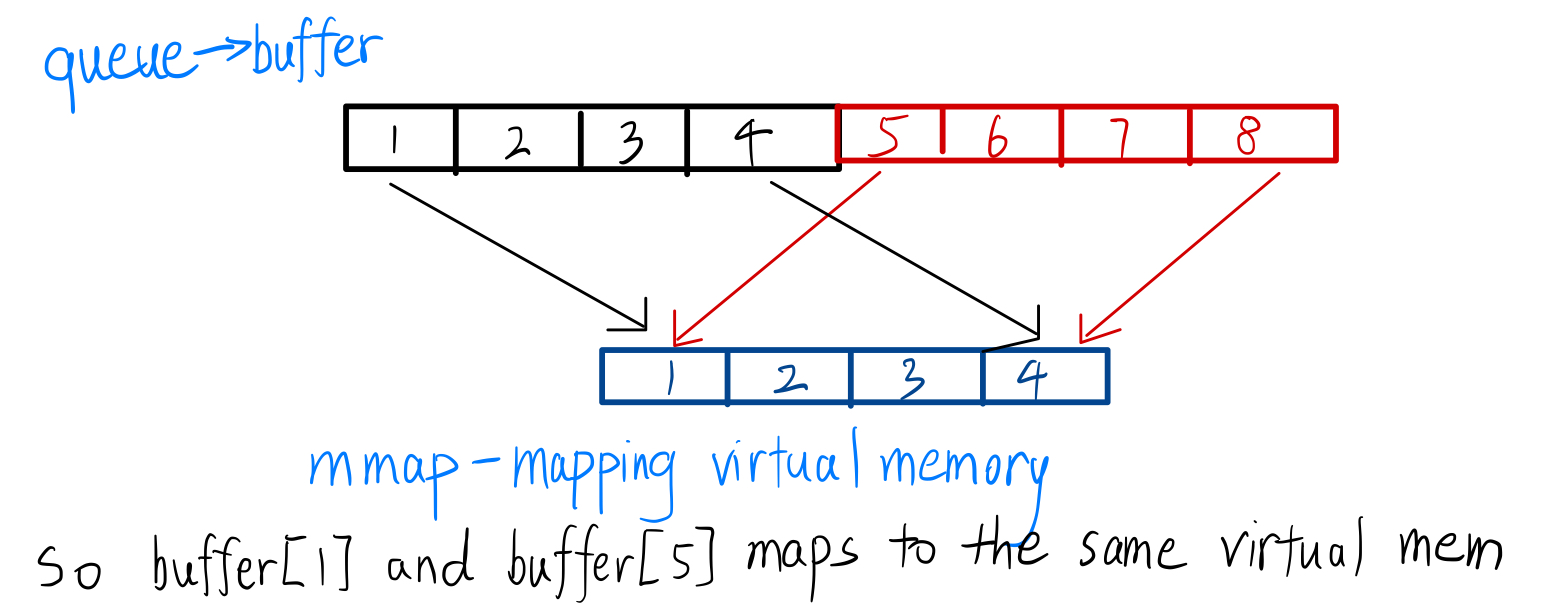
And the code to implement this idea is actually pretty simple. We grab a temporary file descriptor fd to make sure the two mmap calls will be backed up by the same virtual memory through referencing to this fd. And we specify MAP_FIXED flag to mmap to emphasize that operating system must map the memory at exactly the address we provide instead of taking it as a hint.
struct circular_queue *create_queue(size_t size) {
assert(size % getpagesize() == 0);
struct circular_queue *queue = malloc(sizeof(struct circular_queue));
queue->size = size;
queue->write_index = 0;
queue->read_index = 0;
queue->buffer = mmap(NULL, 2 * size, PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
int fd = memfd_create("double_mmap_fd", 0);
ftruncate(fd, size);
mmap(queue->buffer, size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, fd, 0);
mmap(queue->buffer + size, size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, fd, 0);
close(fd);
return queue;
}
void enqueue(struct circular_queue *queue, char *data, size_t len) {
assert(len <= queue->size);
size_t remain = queue->size - queue->write_index;
size_t copy_to_tail = (remain >= len) ? len : remain;
size_t overflow = len - copy_to_tail;
memcpy(queue->buffer+queue->write_index, data, copy_to_tail); // we save 1 extra memcpy when wrapping around
queue->write_index = (queue->write_index + len) % queue->size;
}
To keep this blog concise, I’m skipping detailed performance benchmarks for the double-mmap technique. Curious readers are encouraged to experiment — under frequent wrap-around conditions, it can deliver a noticeable performance boost.
Reference